交通大数据解决方案 数据库开发与管理的核心策略与实践
随着城市化进程的加速和智能交通系统的不断发展,交通大数据已成为优化城市管理、提升出行效率的关键资源。交通大数据解决方案的核心在于高效、可靠的数据库开发与管理,这不仅涉及海量数据的存储与处理,更关乎实时分析、智能决策与系统稳定性。本文将探讨交通大数据背景下数据库开发与管理的核心策略与实践路径。
一、交通大数据的特点与数据库挑战
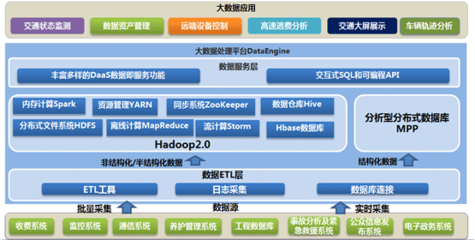
交通大数据通常具备“4V”特征:数据体量巨大(Volume)、来源多样且实时性强(Velocity)、类型复杂(Variety)以及价值密度低但潜在价值高(Value)。例如,交通流量传感器、GPS轨迹、视频监控、移动支付记录等数据源持续产生TB甚至PB级数据。这对数据库系统提出了高并发读写、低延迟响应、弹性扩展与多模态数据支持等严峻挑战。
二、数据库开发的核心策略
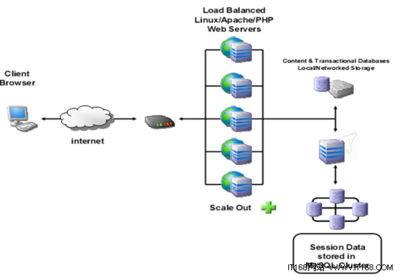
- 分层架构设计:采用分层数据架构,将原始数据、清洗后数据、聚合数据与应用数据分离,提升处理效率。例如,使用分布式存储系统(如HDFS)存储原始日志,通过数据管道(如Kafka+Spark)进行实时流处理,并将结果存入高性能数据库(如ClickHouse或时序数据库)供分析查询。
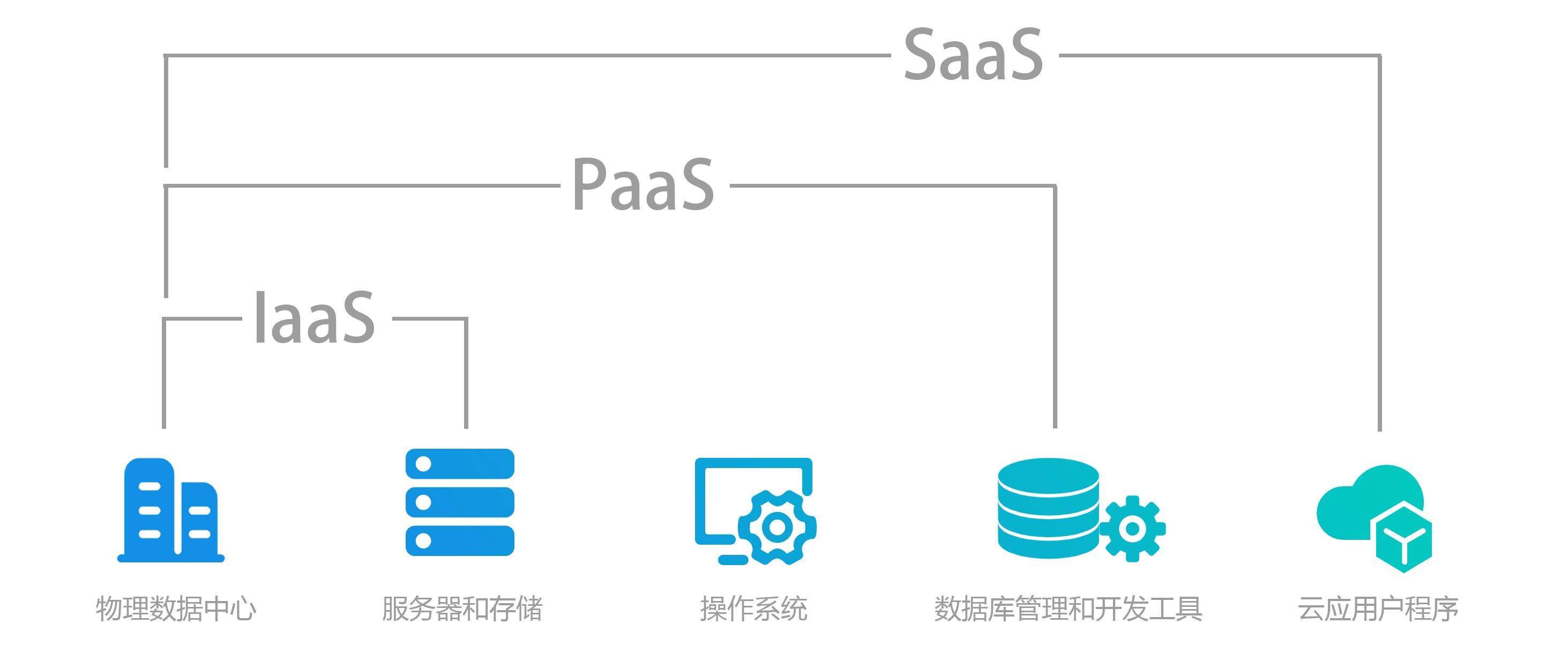
- 多模数据库融合:交通数据包含结构化(如车辆登记信息)、半结构化(如JSON格式的传感器数据)和非结构化数据(如监控视频)。开发中需结合关系型数据库(如PostgreSQL)、NoSQL数据库(如MongoDB存储轨迹数据)与时序数据库(如InfluxDB处理传感器流),通过数据湖或数据中台实现统一访问。
- 实时处理能力:针对交通管控、事故预警等场景,需开发低延迟数据处理模块。利用内存数据库(如Redis)缓存热点数据,并采用流计算框架(如Flink)实现实时流量分析与异常检测。
三、数据库管理的关键实践
- 可扩展性与容灾:交通数据增长迅速,数据库需支持水平扩展。通过分片(Sharding)技术分布数据负载,并设置多副本与跨地域备份,确保系统在硬件故障或网络中断时仍能持续服务。云原生数据库(如AWS Aurora或阿里云PolarDB)提供了自动扩缩容与高可用保障。
- 数据安全与合规:交通数据常包含个人隐私(如出行轨迹),管理上需加密存储、实施访问控制(RBAC)与审计日志。符合GDPR等法规要求,对敏感数据脱敏处理,并通过数据生命周期策略定期归档或清理历史数据。
- 性能监控与优化:建立全方位的监控体系,跟踪查询延迟、吞吐量、存储使用率等指标。利用索引优化、查询重写与缓存策略提升性能;定期进行数据压缩与分区维护,减少存储开销。AI驱动的自治数据库(如Oracle Autonomous Database)可自动执行部分优化任务。
四、案例与未来展望
某智慧城市项目通过搭建混合数据库平台,整合了交通信号数据、公交车GPS与市民卡支付记录,实现了实时拥堵分析与公交调度优化。随着5G与车联网普及,边缘数据库与云边协同管理将成为趋势,同时图数据库(如Neo4j)将更广泛用于交通网络关系分析。数据库开发与管理也需融入数据治理框架,确保数据质量与一致性,最终支撑起智能、绿色、安全的交通体系。
交通大数据解决方案的成功,离不开稳健且灵活的数据库开发与管理。通过结合分层架构、多模存储、实时处理与自动化运维,我们不仅能应对当前的数据挑战,更能为未来智慧交通的演进奠定坚实基础。
如若转载,请注明出处:http://www.guangyuxt.com/product/8.html
更新时间:2026-06-18 13:19:32